

Машинное обучение
Статья обновлена 05.07.2024
Машинное обучение — что это такое? Под machine learning понимают приложение искусственного интеллекта — ИИ, которое может автоматически учиться и совершенствоваться на основе опыта, не будучи явно запрограммированным на это. Машинное обучение происходит в результате анализа постоянно увеличивающихся объемов данных. Поэтому основные алгоритмы не меняются, но меняется внутренний код, используемый для выбора конкретного ответа.

Специалисты по обработке данных называют технологии, используемые для реализации машинного обучения, алгоритмами. Алгоритм — это серия пошаговых операций, обычно вычислений, которые позволяют решить определенную проблему за конечное число шагов. В машинном обучении алгоритмы используют серию конечных шагов для решения проблемы путем обучения на поступающих данных.
Основы машинного обучения
Машинное обучение строится на принципах оптимизации модели, которая является математически обобщенным представлением самих данных, позволяющим спрогнозировать соответствующий ответ. Даже если ИИ получает ввод, которого раньше не видел. Чем точнее модель может давать правильные ответы, тем лучше она извлекает уроки из представленных входных данных. Алгоритм подбирает модель к данным, и этот процесс называется обучением.
Узнать больше и выбрать обучающий курс по машинному обучению на этом сайте.
Возьмем простой график, имитирующий то, что происходит в машинном обучении. В этом случае, начиная с входных значений 1, 4, 5, 8 и 10 и объединяя их в пары с соответствующими выходными значениями 7, 13, 15, 21 и 25, алгоритм машинного обучения определяет, что лучший способ представления связи между входом и выходом определяется формулой. Исходя из наших данных, это 2x + 5 — любая пара в неё укладывается. То есть, например, 4х2 + 5 = 13, 5×2 + 5 = 15 и так далее.
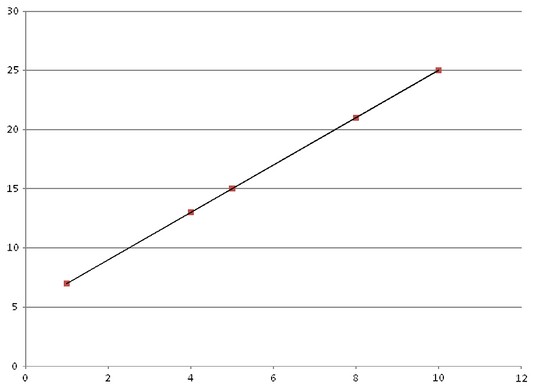
Эта формула и есть определение модели, используемой для обработки всех входных данных — даже новых или пока невидимых — и для вычисления соответствующего выходного значения. Модель использует образец, сформированный алгоритмом, так что новый ввод числа 3 даст прогнозируемый результат 11 = 2х3 + 5.
Хотя большинство сценариев машинного обучения намного сложнее, чем этот, пример дает общее представление о том, что происходит. Вместо того, чтобы индивидуально программировать ответ для ввода 3, ИИ может вычислить правильный ответ на основе пар «ввод-ответ», которые она уже изучила.
Цели машинного обучения
Основная цель машинного обучения заключается в том, что можно представить реальность, используя математическую функцию, которую алгоритм не знает заранее, но которую он может определить после просмотра некоторых данных — всегда в форме парных входов и выходов. То есть каждый алгоритм машинного обучения построен на модифицируемой математической функции. Функцию можно изменить — в результате ИИ может адаптировать её к конкретной информации, взятой из данных. Эта концепция является основной идеей для всех видов алгоритмов машинного обучения.
Обучение в machine learning носит чисто математический характер и заканчивается связыванием определенных входных данных с определенными выходными данными. Это не имеет ничего общего с обучением в том смысле, в каком его понимают люди. Процесс часто называют обучением, потому что алгоритм обучен подбирать правильный ответ — результат — на каждый предложенный вопрос — входные данные.
Несмотря на отсутствие осознанного понимания и то, что машинное обучение является математическим процессом, оно может оказаться полезным для решения многих задач. ИИ дает многим приложениям и программам возможность имитировать рациональное мышление в определенном контексте, когда обучение происходит с использованием правильных данных.
Виды машинного обучения
Машинное обучение предлагает несколько различных способов учиться на поступающих данных. В зависимости от ожидаемого результата и типа вводимых данных можно классифицировать алгоритмы по виду. Выбранный вид зависит от типа имеющихся данных и ожидаемого результата. Для создания алгоритмов используются 4 вида обучения:
- машинное обучение с учителем;
- машинное обучение без учителя;
- самоконтролируемое машинное обучение;
- машинное обучение с подкреплением.
Машинное обучение с учителем
При работе с алгоритмами машинного обучения с учителем входные данные помечаются и имеют определенный ожидаемый результат. Обучение используется, чтобы создать модель, алгоритм которой соответствует данным. По мере обучения прогнозы или классификации становятся более точными. Вот основные методы машинного обучения такого вида с контролируемыми алгоритмами:
- линейная или логистическая регрессия;
- метод опорных векторов, SVM;
- наивный байесовский классификатор;
- метод k-ближайших соседей, KNN.
Необходимо различать задачи регрессии, целью которых является числовое значение, и классификации, где цель — качественная переменная, такая как класс или тег. Задача регрессии может определить средние цены на дома в районе Остоженки, в то время как пример задачи классификации заключается в различении видов цветов ириса на основе размеров чашелистиков и лепестков. Вот несколько примеров машинного обучения с учителем:
- история покупок, в том числе список товаров, которые клиенты никогда не покупали;
- обнаружение и распознавание изображений;
- текст в форме ответов — чат-боты, программные приложения для общения;
- машинный перевод с разных языков;
- аудиорасшифровка текста, распознавание речи;
- изображение или данные с датчиков — рулевое управление, торможение или ускорение, поведенческое планирование для автопилотов.
Машинное обучение без учителя
При работе с алгоритмами машинного обучения без учителя входные данные не помечаются, а результаты неизвестны. В этом случае анализ структур данных дает требуемую модель. Структурный анализ может преследовать несколько целей, например, уменьшение избыточности или группирование похожих данных. Примеры машинного обучения без учителя:
- кластеризация;
- обнаружение аномалий;
- нейронные сети;
- самоконтролируемое машинное обучение.
Обучение с самоконтролем относится к отдельной категории. Некоторые описывают это как автономное обучение, которое имеет все преимущества контролируемого, но без работы, необходимой для маркировки данных.
Машинное обучение с подкреплением
Обучение с подкреплением рассматривается как расширение самостоятельного обучения. Потому что обе формы используют один и тот же подход к обучению с немаркированными данными для достижения схожих целей. Однако обучение с подкреплением добавляет в алгоритм петлю обратной связи. Когда ИИ в результате обучения с подкреплением выполняет задачу правильно, он получает положительную обратную связь, которая укрепляет модель в соединении целевых входов и выходов. Точно так же он может получать отрицательные отзывы о неверных решениях. В некоторых отношениях эта система работает так же, как дрессировка собак, основанная на системе вознаграждений.
Наиболее полное представление обо всех используемых моделях и алгоритмах даёт учебник, который написал эксперт Петер Флах «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных». Частные вопросы по построению разных типов моделей с использованием популярных языков программирования можно найти в соответствующих книгах — например, «Python, машинное обучение».
Задачи машинного обучения
Машинное обучение (МО) — обширная область, охватывающая широкий спектр задач.
В целом, задачи МО можно разделить на три категории:
1. Обучение с учителем
В задачах обучения с учителем алгоритму предоставляется набор обучающих данных, который содержит как входные данные (x), так и желаемые выходные данные (y). Цель алгоритма заключается в изучении зависимости между x и y, чтобы он мог предсказывать y для новых, невиданных ранее входных данных.
Примеры задач обучения с учителем
- Классификация. Определить, к какому классу принадлежит новый элемент данных (например, спам или не спам, изображение кошки или собаки).
- Регрессия. Предсказать числовое значение (например, цена дома или спрос на продукт).
2. Обучение без учителя
В задачах обучения без учителя алгоритму предоставляется набор обучающих данных, который не содержит меток. Цель алгоритма заключается в поиске скрытых закономерностей или структур в данных.
Примеры задач обучения без учителя
- Кластеризация. Сгруппировать похожие элементы данных (например, клиентов по покупательским привычкам).
- Снижение размерности. Уменьшить количество переменных в наборе данных, сохранив при этом наиболее важную информацию.
3. Обучение с подкреплением
В задачах обучения с подкреплением алгоритм взаимодействует с окружающей средой, выполняя действия и получая вознаграждения или штрафы за эти действия. Цель алгоритма заключается в изучении оптимальной политики действий, максимизирующей совокупное вознаграждение.
Примеры задач обучения с подкреплением
- Робототехника: Научить робота выполнять задачи, такие как ходьба или игра в игры.
- Управление игрой: Разработать бота для игры в видеоигры.
Помимо этих трех основных категорий, существует множество других задач МО, таких как обучение с несколькими учителями, активное обучение и трансферное обучение.
Проблемы машинного обучения
Чтобы быть полезной, модель машинного обучения должна представлять общий вид всех обрабатываемых данных. Если модель недостаточно точно им соответствует, то есть обобщение неполное, она не будет работать так, как нужно, и выдаст ошибки.
С другой стороны, если модель слишком внимательно следует за данными и обобщает слишком многое, она «перестарается» — и полученные результаты будут также неточными, растянутыми, как перчатка из-за слишком долгого ношения.
И то, и другое не подходит для эффективной работы с машинным обучением. Только когда модель будет правильно подогнана к данным, она даст результаты в разумном диапазоне ошибок.
Вопрос, насколько нужно обобщать данные, также важен при принятии решения, когда использовать машинное обучение. Искусственный интеллект всегда сводит конкретные примеры до общих примеров того же типа. То, как он выполняет эту задачу, зависит от ориентации решения машинного обучения и алгоритмов, используемых для его работы.
Другая проблема для специалистов по обработке данных и всех, кто использует методы машинного обучения, заключается в том, что компьютер не даёт никаких сигналов, говорящих о том, что модель полностью соответствует данным. Часто решение, достаточно ли обучен алгоритм, чтобы обеспечить хороший обобщенный результат, зависит от человеческой интуиции. Кроме того, создатель решения должен выбрать правильный алгоритм из тысяч существующих. Чтобы процесс машинного обучения работал так, как нужно, специалист по данным должен обладать следующими компетенциями:
- хорошее знание доступных алгоритмов машинного обучения;
- опыт работы с данными, о которых идет речь;
- понимание желаемого результата;
- желание экспериментировать с различными алгоритмами машинного обучения.
Последнее требование является наиболее важным, потому что в этой области нет жестких правил. Конкретный алгоритм будет работать со всеми типами данных во всех возможных ситуациях. Чтобы найти лучший, специалист по данным часто прибегает к экспериментам с рядом алгоритмов и сравнению результатов.
Последняя проблема — это усложнение. Когда дело доходит до машинного обучения, простые решения — всегда лучше. Множество различных алгоритмов могут предоставить полезные результаты, но лучший — это тот, который легче всего понять и который дает наиболее простые результаты. По сути, лучшая стратегия тут это принцип бритвы Оккама — «Не следует множить сущее без необходимости», то есть использование простейшего решения для конкретной проблемы. По мере увеличения сложности увеличивается и вероятность ошибок. Так что определяющим фактором при выборе алгоритма должна быть простота.
- Выясним, какая аналитика требуется для вашего проекта в зависимости от предстоящих задач.
- Подберем оптимальный вариант: начиная от сквозной аналитики на базе Яндекс Метрики или Google Analytics 4 до продвинутой маркетинговой аналитики с моделями атрибуции и когортами.
- Поможем считать CPL, CAC, AOV, LTV, ROAS, ДРР и ROMI.
- Расскажем, как оптимизировать рекламу на целевых пользователей, используя информацию о сделках.
- Отправим доступы к демо-кабинету с примерами отчетов.
Кейсы
Познакомьтесь с историями успеха наших клиентов, которые уже используют решения ROMI center

Продвижение в высококонкурентной тематике — это не только большие бюджеты на рекламу, но и необходимость принятия взвешенных решений для оперативной коррекции стратегии продвижения. Как Sushi Good увеличили доход за счет внедрения сквозной аналитики — читайте в кейсе.
Подробнее
Финансовая и кредитная тематика требует углубленной работы с сегментами целевой аудитории. Как нашему клиенту, кредитному брокеру из Санкт-Петербурга, удалось оптимизировать бюджет и правильно сегментировать целевых пользователей с помощью внедрения аналитики?
Подробнее
Как быстро собирать отчеты об эффективности рекламы, фиксировать путь лидов по каждой из ступеней продаж с помощью коннекторов, а также экономить силы на сборе аналитики — рассказываем в кейсе.
Подробнее
Сбор аналитики для интернет-агентства для множества клиентов — ежедневная задача менеджеров. Как с помощью коннекторов ROMI center клиент экономит время на рутинных задачах, и с легкостью масштабирует рекламные кампании заказчиков — читайте в кейсе.
Подробнее
Когда над каждым каналом рекламы работает отдельный подрядчик, архи важно систематизировать все результаты продвижения в режиме единого окна: расходы на рекламу и доходы с нее. В кейсе рассказываем, как DIVA полностью систематизировали данные по трафику.
Подробнее
Можно ли в условиях кризиса увеличить доход в узком сегменте? Да, принимая взвешенные маркетинговые решения и ориентируясь на точные цифры, а не на собственные догадки. В кейсе рассказываем историю клиента, который увеличил прибыль с рекламы на 300% пока его конкуренты закрывались один за одним.
Подробнее